本文是 GB 18030-2022《信息技术 中文编码字符集》的正文电子版。原 PDF 来自互联网档案馆。
附录 A-E 已经被 mrhso 录入了。不过他没录入正文部分。然后我就录入了(
另外本人似乎就是在档案馆里头看到了电子版的 GB 18030-2005 正文,但可惜没找到(或许没了?)
实际上这玩意原先是 Markdown,但是还是转成 HTML 因为这玩意识别到 HTML 标签就把剩下所有玩意全当 HTML 使了
1 范围
本文件规定了信息技术用的中文图形字符及其二进制编码的十六进制表示。
本文件适用于中文和其他文字图形字符信息的处理、交换、存储、传输、显现、输入和输出。
本文件适用于为具备中文和其他文字图形字符信息化处理及交换功能的技术类产品,包括但不限于以输入法、光学字符识别(OCR)、编辑校对、机器翻译、语音合成、文字转写、智能写作等为代表的软件产品,以及以计算机、通信终端设备、电子书阅读器、学习机等为代表的硬件产品。
2 规范性引用文件
下列文件中的内容通过文中的规范性引用而构成本文件必不可少的条款。其中,注日期的引用文件,仅该日期对应的版本适用于本文件;不注日期的引用文件,其最新版本(包括所有的修改单)适用于本文件。
GB/T 2312—1980 信息交换用汉字编码字符集基本集
GB/T 11383—1989 信息处理信息交换用八位代码结构和编码规则
GB/T 13000 信息技术通用多八位编码字符集(UCS)
3 术语和定义
下列术语和定义适用于本文件。
3.1
字符 character
供组织、控制或表示数据用的元素集合中的一个元素。
3.2
编码字符 coded character
字符(3.1)及其编码表示。
3.3
用户自定义区 private use area
使用符合本文件的产品的使用者可以自行规定的区域。
3.4
字汇 repertoire
用编码字符(3.2)集表示的一个指定的字符(3.1)集合。
3.5
保留区 reversed zone
留作未来本文件规定的区域。
4 字汇
4.1 概述
本文件收录的字符以单字节、双字节或四字节编码。
4.2 单字节部分
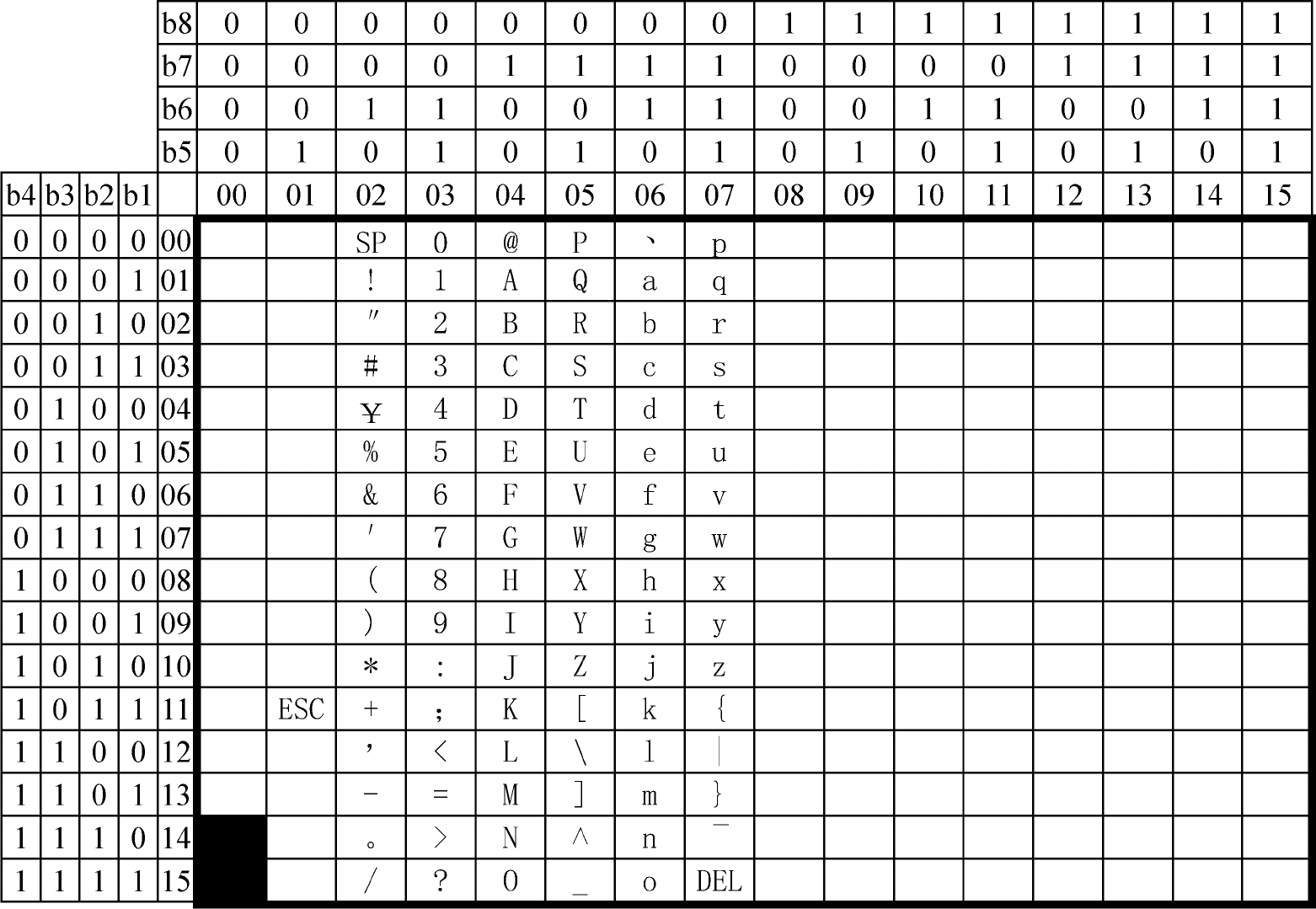
单字节部分收录了 GB/T 11383—1989 的 0x00~0x7F 全部 128 个字符。
4.3 双字节部分
双字节部分收录了 GB/T 2312—1980 中的全部图形字符、GB/T 13000 中的 CJK 统一汉字以及部分图形字符。双字节部分的字符按照附录 A 的规定。其中,表意文字描述符的图形、代码位置和功能应符合附录 B 的规定。
注: GB/T 13000对中国、日本、韩国、越南等国家和地区使用的汉字统一编码。具备独有抽象字形的汉字,赋予单 独的代码位置;来源不同而抽象字形相同的汉字,则赋予共用的代码位置。经过编码的汉字称为 CJK 统一汉字 (CJK Unified Ideographs),其中 CJK 表示中国、日本、韩国。
4.4 四字节部分
四字节部分收录了上述双字节字符之外的 GB/T 13000 中的 66 个 CJK 统一汉字(9FA6~9FEF, 不包括 9FB4~9FBB 的 8 个字符)、CJK 统一汉字扩充 A、CJK 统一汉字扩充 B、CJK 统一汉字扩充 C、CJK 统一汉字扩充 D、CJK 统一汉字扩充 E、CJK 统一汉字扩充 F 和已经在 GB/T 13000 中编码的少数 民族文字的字符。四字节部分的字符按照附录 C 的规定。
5 总体结构
正文中凡数字前标有 0x 的表示采用十六进制,未标有 0x 的表示采用十进制。附录中凡编码的表示均采用十六进制,其他数字的表示均采用十进制。
单字节部分采用 GB/T 11383—1989 的编码结构,使用 0x00~0x7F 码位。
双字节部分采用两个八位二进制位串表示一个字符,其首字节码位从 0x81~0xFE,尾字节码位分别是 0x40~0x7E 和 0x80~0xFE。
四字节部分采用 GB/T 11383—1989 未采用的 0x30~0x39 作为对双字节编码扩充的后缀,编码范围为 0x81308130~0xFE39FE39。四字节字符的第一个字节编码范围为 0x81~0xFE;第二个字节编码范围为 0x30~0x39;第三个字节编码范围为 0x81~0xFE;第四个字节编码范围为 0x30~0x39。即: 0x81308130~0x81308139;
0x81308230~0x81308239;
......
0x8130FE30~0x8130FE39;
0x81318130~0x81318139;
......
0x8131FE30~0x8131FE39;
......
0x82308130~0x82308139;
......
0x8230FE30~0x8230FE39;
......
0xFE308130~0xFE308139;
......
0xFE39FE30~0xFE39FE39。
总体结构与码位范围分配见图 1 和表 1。
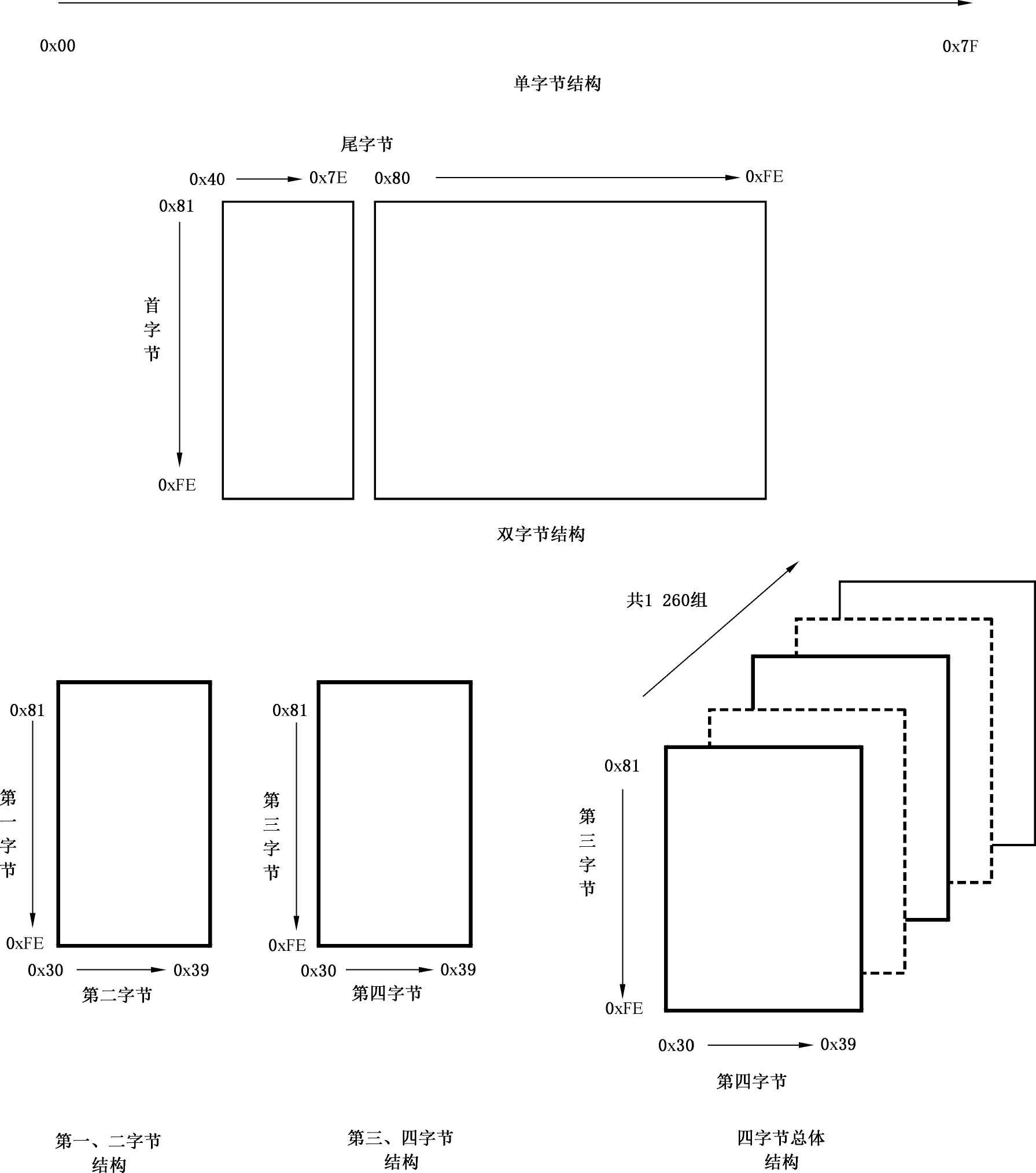
| 编码类型 | 码位空间 | 码位数目 | |||
|---|---|---|---|---|---|
| 单字节 | 0x00~0x7F | 128 | |||
| 双字节 | 第一字节 | 第二字节 | 23940 | ||
| 0x81 ~ 0xFE | 0x40 ~ 0x7E,0x80 ~ 0xFE | ||||
| 四字节 | 第一字节 | 第二字节 | 第三字节 | 第四字节 | 1587600 |
| 0x81~ 0xFE | 0x30~ 0x39 | 0x81~ 0xFE | 0x30~ 0x39 | ||
6 字符的排列顺序
6.1 单字节部分字符的排列顺序
单字节部分字符按照 GB/T 11383—1989 中相应字符的顺序排列。
6.2 双字节部分字符的排列顺序
双字节部分字符排列顺序应符合附录 A。
6.3 四字节部分字符的排列顺序
自 0x81308130 至 0x8439FE39 共 50400 个码位,对应双字节部分未包括的所有 GB/T 13000 基本多文种平面的字符,按照 GB/T 13000 基本多文种平面相应字符的顺序排列。
自 0x90308130 至 0xE339FE39 共 1058400 个码位用于对应 GB/T 13000 的 16 个辅助平面,字符排列顺序完全按照 GB/T 13000的 16 个辅助平面的相应码位顺序依次排列。
四字节部分字符排列顺序应符合附录 C。
7 码位分配
7.1 单字节部分的码位分配
单字节部分的码位按照 GB/T 11383—1989 的规则分配。单字节码位分配见图 2。
7.2 双字节部分的码位分配
双字节部分的码位安排分为 0x8140~0xFE7E 和 0x8180~0xFEFE 两部分 , 共 23940 个码位。双字节码位分配见图 3 及表 2 。
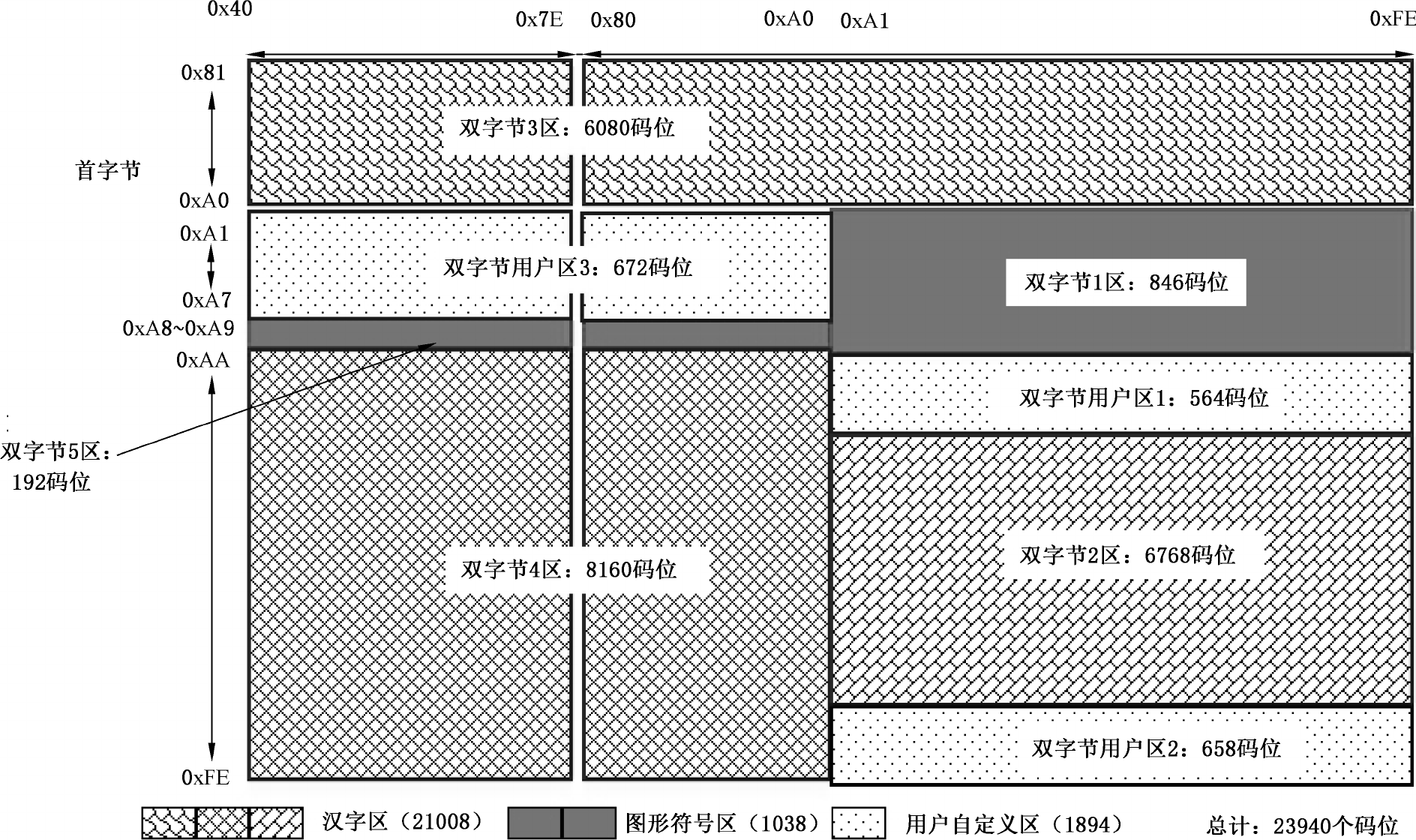
| 类别 | 区名 | 码位范围 | 码位数 | 字符数 | 字符类型 |
|---|---|---|---|---|---|
| 符号区 | 双字节 1 区 |
首字节 0xA1~0xA9 尾字节 0xA1~0xFE |
846 | 728 | 图形符号 |
| 双字节 5 区 |
首字节 0xA8~0xA9 尾字节 0x40~0x7E 和 0x80~0xA0 |
192 | 166 | 图形符号 | |
| 汉字区 | 双字节 2 区 |
首字节 0xB0~0xF7 尾字节 0xA1~0xFE |
6768 | 6763 | 汉字 |
| 双字节 3 区 |
首字节 0x81~0xA0 尾字节 0x40~0x7E 和 0x80~0xFE |
6080 | 6080 | 汉字 | |
| 双字节 4 区 |
首字节 0xAA~0xFE 尾字节 0x40~0x7E 和 0x80~0xA0 |
8160 | 8145 | 汉字 | |
| 用户自定义区 | 双字节用户区 1 |
首字节 0xAA~0xAF 尾字节 0xA1~0xFE |
564 | ||
| 双字节用户区 2 |
首字节 0xF8~0xFE 尾字节 0xA1~0xFE |
658 | |||
| 双字节用户区 3 |
首字节 0xA1~0xA7 尾字节 0x40~0x7E 和 0x80~0xA0 |
672 |
7.3 四字节部分的码位分配
四字节部分收录了汉字和部分少数民族文字。四字节码位分配见表 3。表 3 中没有指明的四字节码位分配见 6.3。
| 码位范围 | 码位数 | 字符数 | 字符类型 |
|---|---|---|---|
| 0x81318132~0x81319934 | 243 | 42 | 维吾尔、哈萨克、柯尔克孜文 |
| 0x8430BA32~0x8430FE35 | 684 | 59 | 维吾尔、哈萨克、柯尔克孜文 |
| 0x84318730~0x84319530 | 141 | 84 | 维吾尔、哈萨克、柯尔克孜文 |
| 0x8132E834~0x8132FD31 | 208 | 193 | 藏文 |
| 0x8134D238~0x8134E337 | 170 | 149 | 蒙古文(包括满文、托忒文、锡伯文和阿礼嘎礼字) |
| 0x9034C538~0x9034C730 | 13 | 13 | 蒙古文 BIRGA |
| 0x8134F434~0x8134F830 | 37 | 35 | 德宏傣文 |
| 0x8134F932~0x81358437 | 96 | 83 | 西双版纳新傣文 |
| 0x81358B32~0x81359935 | 144 | 127 | 西双版纳老傣文 |
| 0x82359833~0x82369435 | 1223 | 1215 | 彝文 |
| 0x82369535~0x82369A32 | 48 | 48 | 傈僳文 |
| 0x81339D36~0x8133B635 | 250 | 69 | 朝鲜文字母 |
| 0x8139A933~0x8139B734 | 142 | 51 | 朝鲜文兼容字母 |
| 0x8237CF35~0x8336BE36 | 11172 | 3431 | 朝鲜文音节 |
| 0x9232C636~0x9232D635 | 160 | 133 | 滇东北苗文 |
| 0x81398B32~0x8139A135 | 224 | 214 | 康熙部首 |
| 0x8139EE39~0x82358738 | 6530 | 6530 | CJK 统一汉字扩充 A |
| 0x82358F33~0x82359636 | 74 | 66 | CJK 统一汉字 |
| 0x95328236~0x9835F336 | 42711 | 42711 | CJK 统一汉字扩充 B |
| 0x9835F738~0x98399E36 | 4149 | 4149 | CJK 统一汉字扩充 C |
| 0x98399F38~0x9839B539 | 222 | 222 | CJK 统一汉字扩充 D |
| 0x9839B632~0x9933FE33 | 5762 | 5762 | CJK 统一汉字扩充 E |
| 0x99348138~0x9939F730 | 7473 | 7473 | CJK 统一汉字扩充 F |
其他未占用的四字节码位为保留区,留待未来文件扩展使用。
8 部分字符和代码的说明
相对于 GB 18030—2005,部分代码位置上的字形和/或所对应的GB/T 13000 代码位置在本文件中进行了调整(见附录 D)。
9 实现的级别
9.1 通则
本文件规定三个实现级别。符合相应实现级别的系统软件产品,应提供相应实现级别范围内全部字符的输入输出功能。
9.2 实现级别1
实现级别 1 支持本文件的单字节编码部分、双字节编码部分和四字节编码部分的 CJK 统一汉字(即 0x82358F33~0x82359636)和 CJK统一汉字扩充A (即0x8139EE39~0x82358738)。 任何本文件适用的产品均应满足实现级别1的要求。
注: 根据软件应用需要,实现级别1还可选择支持表3列出的任何一种或多种非汉字文种。
9.3 实现级别2
实现级别 2 包含实现级别 1。此外,实现级别 2 还支持《通用规范汉字表》中的没有包含在实现级别 1 之内的编码汉字。《通用规范汉字表》所收汉字在本文件中的代码位置和字形,见附录 E。 系统软件及支撑软件,应满足实现级别 2 的要求。
注: 系统软件及支撑软件包括但不限于操作系统、数据库管理系统、中间件(软件产品分类的信息见 GB/T 36475)。
9.4 实现级别3
实现级别 3 包含实现级别 2。此外,实现级别 3 还支持本文件规定的全部汉字及表3中的康熙部首。 用于政务服务和公共服务的产品应满足实现级别 3 的要求。
注: 政务服务和公共服务行业包括但不限于铁路运输业、道路运输业、水上运输业、航空运输业、多式联运和运输代理业、邮政业、货币金融服务、保险业、土地管理业、卫生、国家机构、社会保障等(行业分类的信息见 GB/T 4754)。
附录(略)
参考文献
[1] GB/T 4754 国民经济行业分类
[2] GB/T 36475 软件产品分类
[3] 通用规范汉字表.中华人民共和国国务院(国发〔2013〕23 号).